Guest Wieschie On Ocr
This is guest written by [RTI] Wieschie. He has written the OCR component of VOID’s PPK workflow. Here is him describing highlights of solving that!
Killmail OCR Development
Killmails are many things in Eve - they can be bragging rights, ways to track enemy movements, tactics, and fits, or just a mess that everyone wants to gather around and stare out. Eve Online provides a killmail API that allows players to develop a rich set of 3rd party tools that have access to all of this data. Unfortunately, the best we can get in Eve Echoes is player-submitted screenshots. Screenshots are nice to share with your friends, but it’s impossible to glean anything from them on a larger scale. So the solution has become creating software that can read these screenshots and extract the data we need.
I have set out to build a free and open-source killmail parser for Eve Echoes.
Many other parsers are using machine vision APIs from cloud services to pull text from images. This is fast, easy, supports more types of scripts and languages, and can be very accurate. However, it costs money and locks you into a specific cloud provider. We want something that we can tinker with and reliably self-host without worrying if a service will increase in price or a third party bot will go down.
Using Tesseract
Tesseract is a free Optical Character Recognition (OCR) engine. You feed it a picture and it spits out text. There are 3 basic steps when processing an image using OCR:
- Image Pre-processing
- OCR Execution
- Text Post-processing
Image Pre-processing
Tesseract uses an LSTM neural network to transform images into text. There’s a bunch of fancy math behind it, but practically it means that you need a model to tell the software how to translate an image of text into the actual characters it contains. OCR is widely used to digitize scans of printed text, and so these models are trained to recognize black text on a white background. This is nearly the exact opposite of what we get in killmails. Most text is white or lightly saturated colors, on a dark or patterned background. Cleaning this up first helps us get better results.
Here’s a killmail header. The background is fairly clean, but the color scheme is not quite right.

# convert our image to grayscale
img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# invert the colors so the text is black
img = cv2.bitwise_not(img)
And viola!

Here’s a more complex example. The victim name is pure white text on a background with a space pattern that changes colors based on the type of ship that was killed. This variation in the background can really confuse OCR.

# Convert our image from BGR (Blue-Green-Red) to HSV (Hue-Saturation-Value) to make this kind of filtering easier.
cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# Define an HSV range that the text we want to parse falls inside, while the background falls outside
low = (0, 0, 180)
high = (255, 80, 255)
# inRange returns a 255 if the source pixel is inside the HSV window and 0 when outside. This will result in white text and a black background
img = cv2.inRange(img, low, high)
# invert our image to get black text on a white background
img = cv2.bitwise_not(img)
With a little cleanup, we get an image that looks a little rougher but is very straightforward to identify what is text and what is not. This is called binarization - reducing an image to only 2 values - black and white.

OCR Execution
Using Tesseract is really straightforward - you give it an image, and it gives you text back. There are a few knobs you can tweak to get better results.
import pytesseract as pt
pt.image_to_string(img, lang="eng-shentox", config="--psm 7")
First, Tesseract offers script detection - given an image of text, it will attempt to tell you the written script (such as Latin, Han, Hangul, etc.) that the text is using. This allows us to then choose the best model to parse the text.
Tesseract has a variety of runtime config options, including page-segmentation mode. This is essentially how Tesseract will chop up the image into pieces when looking for text characters. Trying different options can yield better results.
Tesseract is optimized to recognize whole words from a dictionary. Because much of the text we are trying to recognize is either nonsense (character names) or non-word phrases, we can disable the default dictionary or substitute it with our own list of Eve terms that we expect to see.
In addition, you can ask Tesseract for detailed information about the locations that text was identified, and how confident it is that the text was correctly transcribed. It may be useful in the future to look at confidence levels and attempt different methods to see if a more accurate result can be achieved.
Text Post-processing
Now that we’ve processed our images, we’re left with a bunch of text.
Corp tags are one of more frequent culprits for errors. Tesseract often returns text that looks like [ABCJPilot or (ABC]Pilot. These can be cleaned up with some simple find and replace operations.
System names can be difficult to get exactly right. The good news is that we know what all systems in the game are named. So instead of returning the raw text from the image, we can pick the closest-matching actual system and use that value.
from thefuzz import process
# a list of all system > constellation > region pairs in New Eden
systems = load_systems()
# the raw location parsed from the image. There's two incorrectly identified characters here
location = "E1UU-B < 3WN-IT < Esoteria"
# perform a fuzzy text lookup to recieve the closest match and its score
actual_location, location_confidence = process.extractOne(location, systems)
print(f"{actual_location}, {location_confidence}")
> "E1UU-3 < 3WN-1T < Esoteria", 92
Fine Tuning Tesseract
Tesseract has a high level of accuracy on common fonts that you would expect to see in print. It does fairly well with screenshots of text, but the model can get tripped up on specific characters or combinations with a new font that it hasn’t trained on. Is that H or |-|? The brackets in corp tag like [ABC] can be confused with any of these characters: Il|i1)}J.
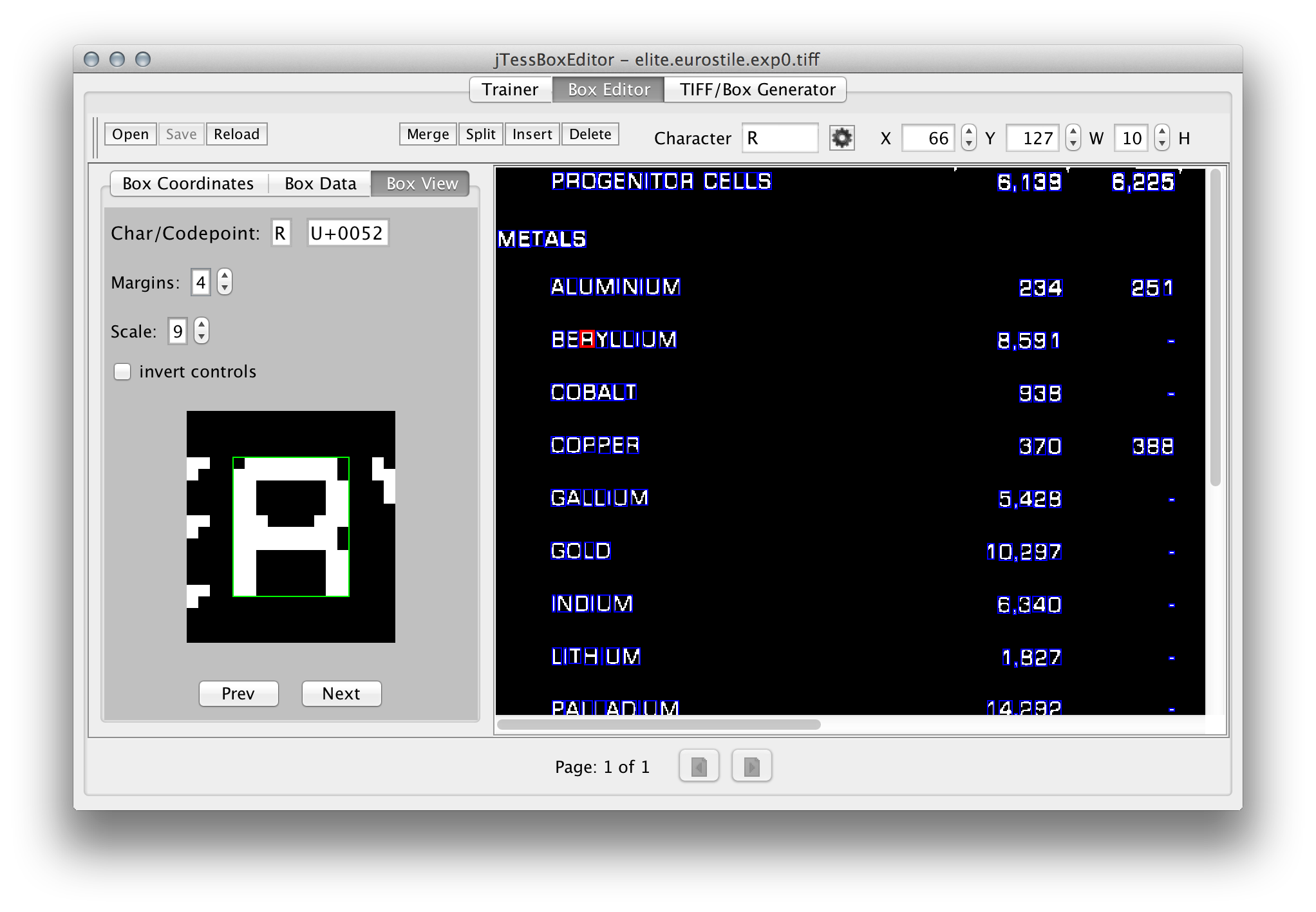
Creating a model requires a set of training data. This data consists of questions (images containing text) and answers (the exact coordinates of every single character and its value). This can be a very labor-intensive process if you are training on photographs. Some poor person has to draw a pixel-perfect box around every character separately and type in the correct value.
{kind=link}
Thankfully, if you have a copy of the font you are trying to recognize, there’s an easier way. Tesseract provides scripts that will generate images and boxes given any sample text and a font. This data can then be used to refine the existing models - taking most of the performance of the original, but cleaning up some of the edge cases. This process is described in detail in their documentation. Eve Echoes uses the Shentox Light font.
You can support VOID’s PPK and other tech: ![]()